Cuda基础操作
本文介绍GPU结构以及Cuda编程。
1、SIMT SIMD等结构
SIMD:单指令多数据
单指令同时操作多个数据元素,数据被打包到宽寄存器中,所有数据执行相同的操作。
硬件依赖:由 CPU 的向量寄存器(如 SSE、AVX)实现。
适用场景:规则数据并行任务(如数组运算、图像滤波)。
工作流程示例:4个浮点数加法(使用128位SIMD寄存器)
- 数据加载:
将4个单精度浮点数(32位)从内存加载到SIMD寄存器(如
XMM0和XMM1)。例如:
XMM0 = [A, B, C, D],XMM1 = [E, F, G, H]。
- 指令执行:
- 单条指令
ADDPS XMM0, XMM1执行四个浮点数的并行加法:
1 | XMM0 = [A+E, B+F, C+G, D+H] |
- 结果存储:
- 将
XMM0中的结果写回内存,完成4个浮点数的加法。
关键特性
严格同步:所有数据元素必须同时执行相同的操作,不支持条件分支。
高效但局限:适合规则计算,但无法处理线程间独立逻辑。
SIMT:单指令多线程
核心特点
单指令控制多个线程,每个线程独立处理数据,允许条件分支(但分支分歧会降低性能)。
硬件依赖:由 GPU 的流多处理器(SM)实现。
适用场景:复杂并行任务(如图形渲染、深度学习)。
工作流程示例:GPU处理像素着色器(32线程的线程束)
- 线程分组:
- 将32个线程打包为一个线程束(Warp),每个线程处理一个像素的着色计算。
- 指令发射:
- 线程束中的所有线程同时接收同一指令,例如:
1 | if (pixel.r > 0.5) |
- 分支处理:
分支分歧:假设16个线程满足条件(路径1),另外16个不满足(路径2)。
串行执行:
GPU先为路径1的16个线程执行
pixel.r = 1.0,路径2的线程被暂停(掩码禁用)。再为路径2的16个线程执行
pixel.r = 0.0,路径1的线程被暂停。
- 结果合并:
- 所有线程完成分支后,继续执行后续指令(如写入显存)。
关键特性
动态分支:允许线程独立执行不同逻辑,但分歧会导致性能损失。
高吞吐量:通过大量线程掩盖内存延迟,适合大规模并行任务。
2、 SIMD vs SIMT 的对比实例
场景:对数组元素执行条件加法
- 任务:对数组
arr中的每个元素,若大于阈值T,则加1,否则减1。
SIMD 的实现(假设4元素并行)
加载数据:将4个元素加载到寄存器
V0 = [a, b, c, d]。条件判断:
SIMD无法直接处理条件分支,需通过向量化条件掩码实现:
- 生成掩码
MASK = [a>T, b>T, c>T, d>T]。
- 生成掩码
- 并行计算:
- 使用掩码选择加1或减1:
1 | V1 = V0 + 1; // 所有元素加1 |
- 写入内存:将结果写回数组。
局限:所有分支路径必须预先计算,无法跳过无效计算。
SIMT 的实现(每个线程处理一个元素)
线程分配:每个线程处理一个元素(如线程0处理
arr[0])。条件判断:
- 线程独立执行:
1 | if (arr[i] > T) { |
- 分支执行:
- 若线程束中部分线程走路径1,部分走路径2,GPU会串行执行两段代码。
- 结果写入:所有线程独立更新数组元素。
- 优势:逻辑直观,适合复杂条件;劣势:分支分歧时性能下降。
3、CPU和GPU结构
一、CPU(中央处理器)
1. 设计目标
CPU 是计算机的“大脑”,注重低延迟和通用性,擅长处理复杂逻辑、分支预测、顺序任务。例如:操作系统调度、应用程序逻辑、数据库查询等。
2. 核心结构
控制单元(Control Unit)
负责指令解码、分支预测(如流水线技术),确保指令按顺序或乱序执行。算术逻辑单元(ALU)
执行整数、浮点运算,现代CPU通常包含多个ALU以支持并行指令(如超标量架构)。缓存系统(Cache Hierarchy)
L1缓存(分指令/数据缓存):极低延迟,约4-64KB。
L2缓存:较大(256KB-2MB),平衡速度与容量。
L3缓存(共享缓存):多核共享,容量可达数十MB。
寄存器
直接与ALU交互的极速存储单元(如x86的RAX、ARM的X0寄存器)。内存控制器
管理对系统内存(如DDR4/DDR5)的访问,延迟低但带宽有限(约50GB/s)。
3. 典型特征
核心数量少:消费级CPU通常4-16核。
高时钟频率:3-5 GHz,通过超线程(Hyper-Threading)提升线程利用率。
复杂分支预测:通过预测执行(Speculative Execution)减少流水线停顿。
二、GPU(图形处理器)
1. 设计目标
GPU 专为高吞吐量并行计算优化,适合处理大量相似任务(如像素渲染、矩阵运算)。典型应用:游戏渲染、深度学习训练、科学模拟。
2. 核心结构
流多处理器(Streaming Multiprocessor, SM)
CUDA核心(NVIDIA)/ 流处理器(AMD):每个SM包含数十至数百个计算单元。
Warp调度器:管理线程束(Warp),以SIMT(单指令多线程)模式执行。
共享内存(Shared Memory):SM内高速缓存(64KB-192KB),用于线程间通信。
全局显存(VRAM)
GDDR6/HBM2显存,带宽高达1TB/s(如NVIDIA RTX 4090带宽为1TB/s)。特殊功能单元
RT Core(光线追踪)、Tensor Core(AI加速)等专用硬件。
3. 典型特征
海量核心:NVIDIA A100 GPU含6912 CUDA核心。
高内存带宽:显存带宽是CPU的10-20倍。
SIMD/SIMT并行:单指令同时操作多个数据(如32线程为一个Warp执行相同指令)。
下图所示:

为CPU和GPU两者的结构。
上图中:
绿色代表的是computational units(可计算单元) 或者称之为 cores(核心),
橙色代表memories(内存) ,
黄色代表的是control units(控制单元)。
计算单元(cores):
由图可以知道,CPU的计算单元是“大”而“少”的,然而GPU的计算单元是“小”而“多”的。
GPU的微观物理结构:
NVidia Tesla架构

拥有7组TPC(Texture/Processor Cluster,纹理处理簇)
每个TPC有两组SM(Stream Multiprocessor,流多处理器)
每个SM包含:
6个SP(Streaming Processor,流处理器)
2个SFU(Special Function Unit,特殊函数单元)
L1缓存、MT Issue(多线程指令获取)、C-Cache(常量缓存)、共享内存
除了TPC核心单元,还有与显存、CPU、系统内存交互的各种部件。
仅仅展示一种结构的GPU,其余大同小异。
GPU架构的共性:
GPC
TPC
Thread
SM、SMX、SMM
Warp
SP
Core
ALU
FPU
SFU
ROP
Load/Store Unit
L1 Cache
L2 Cache
Memory
Register File
GPU工作机制:
从Fermi开始NVIDIA使用类似的原理架构,使用一个Giga Thread Engine来管理所有正在进行的工作,GPU被划分成多个GPCs(Graphics Processing Cluster),每个GPC拥有多个SM(SMX、SMM)和一个光栅化引擎(Raster Engine),它们其中有很多的连接,最显著的是Crossbar,它可以连接GPCs和其它功能性模块(例如ROP或其他子系统)。
程序员编写的shader是在SM上完成的。每个SM包含许多为线程执行数学运算的Core(核心)。例如,一个线程可以是顶点或像素着色器调用。这些Core和其它单元由Warp Scheduler驱动,Warp Scheduler管理一组32个线程作为Warp(线程束)并将要执行的指令移交给Dispatch Units。
GPU中实际有多少这些单元(每个GPC有多少个SM,多少个GPC ……)取决于芯片配置本身。例如,GM204有4个GPC,每个GPC有4个SM,但Tegra X1有1个GPC和2个SM,它们均采用Maxwell设计。SM设计本身(内核数量,指令单位,调度程序……)也随着时间的推移而发生变化,并帮助使芯片变得如此高效,可以从高端台式机扩展到笔记本电脑移动。

如上图,对于某些GPU(如Fermi部分型号)的单个SM,包含:
32个运算核心 (Core,也叫流处理器Stream Processor)
16个LD/ST(load/store)模块来加载和存储数据
4个SFU(Special function units)执行特殊数学运算(sin、cos、log等)
128KB寄存器(Register File)
64KB L1缓存
全局内存缓存(Uniform Cache)
纹理读取单元
纹理缓存(Texture Cache)
PolyMorph Engine:多边形引擎负责属性装配(attribute Setup)、顶点拉取(VertexFetch)、曲面细分、栅格化(这个模块可以理解专门处理顶点相关的东西)。
2个Warp Schedulers:这个模块负责warp调度,一个warp由32个线程组成,warp调度器的指令通过Dispatch Units送到Core执行。
指令缓存(Instruction Cache)
内部链接网络(Interconnect Network)
GPU资源机制:
1、内存架构:
部分架构的GPU与CPU类似,也有多级缓存结构:寄存器、L1缓存、L2缓存、GPU显存、系统显存。

GPU Context和延迟:
由于SIMT技术的引入,导致很多同一个SM内的很多Core并不是独立的,当它们当中有部分Core需要访问到纹理、常量缓存和全局内存时,就会导致非常大的卡顿(Stall)。
例如下图中,有4组上下文(Context),它们共用同一组运算单元ALU。
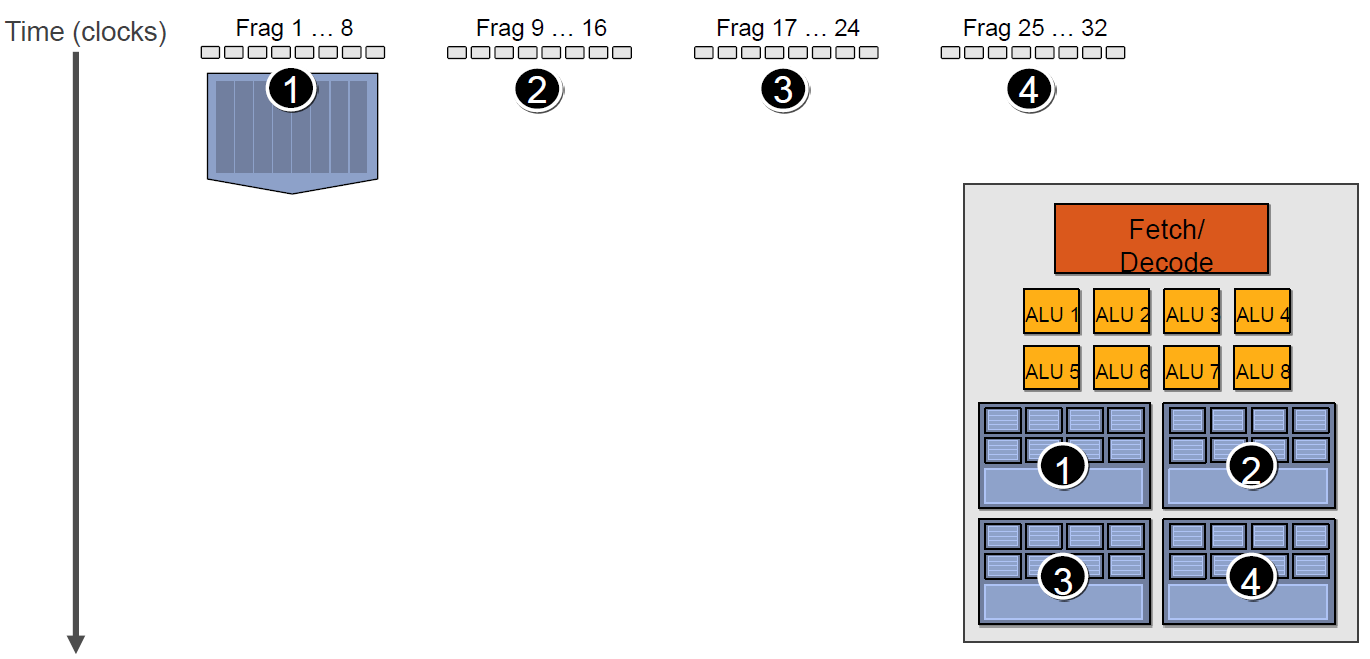
假设第一组Context需要访问缓存或内存,会导致2~3个周期的延迟,此时调度器会激活第二组Context以利用ALU:
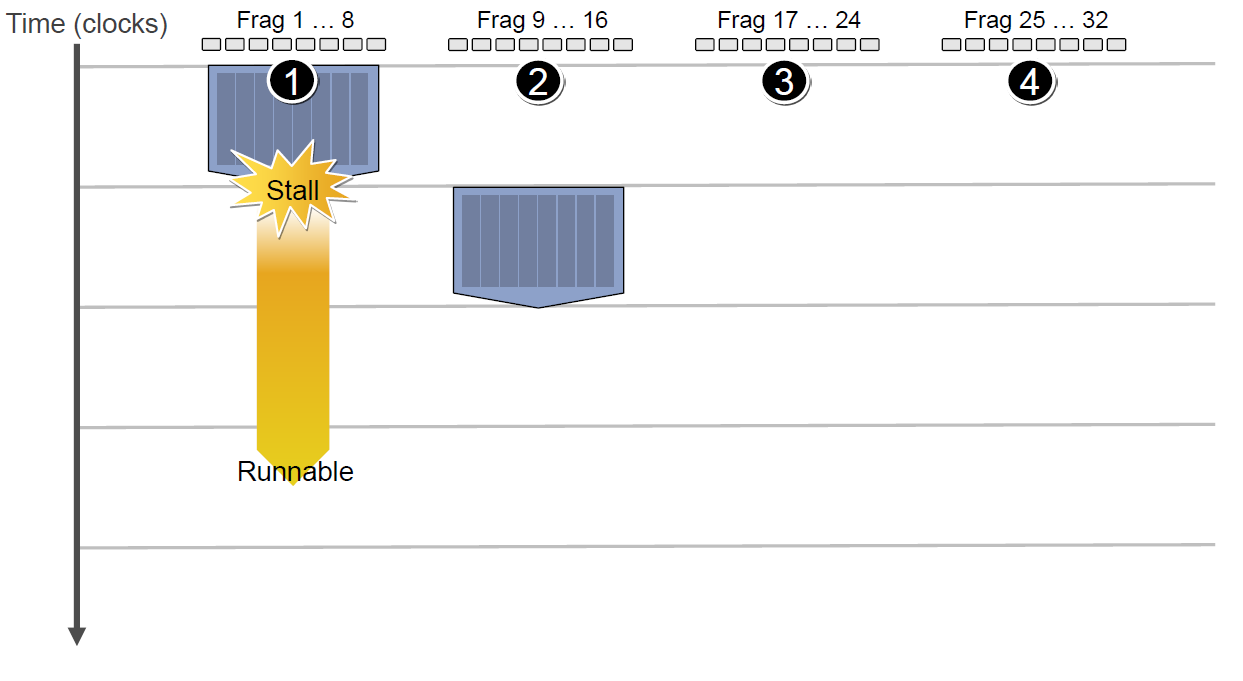
当第二组Context访问缓存或内存又卡住,会依次激活第三、第四组Context,直到第一组Context恢复运行或所有都被激活:
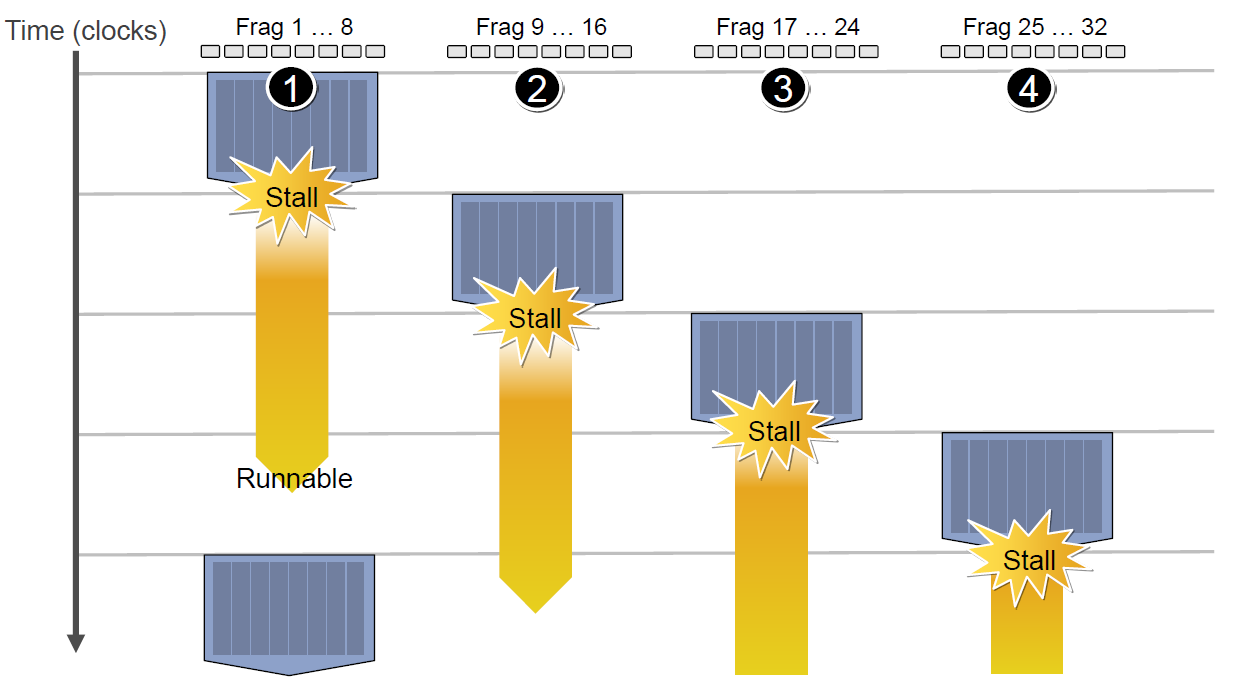
延迟的后果是每组Context的总体执行时间被拉长了:
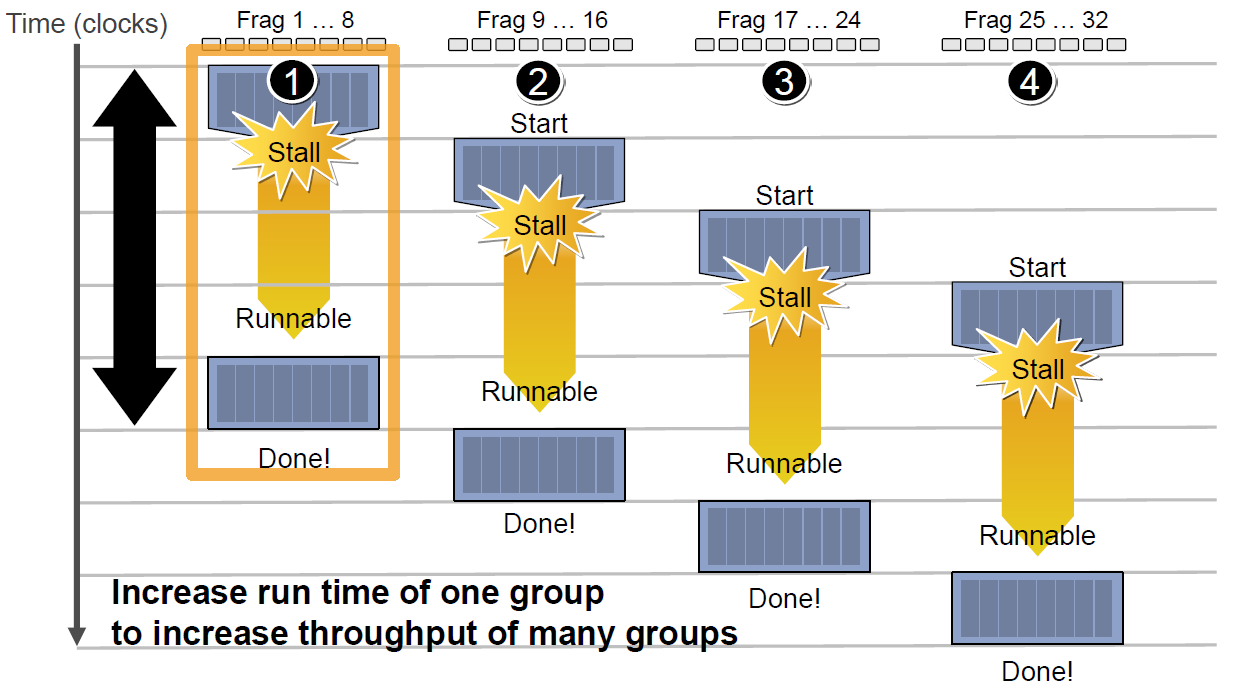
但是,越多Context可用就越可以提升运算单元的吞吐量,比如下图的18组Context的架构可以最大化地提升吞吐量:
![]https://cdn.jsdelivr.net/gh/GaryAacm/image-hosting@main/Cuda/5.png()
CPU-GPU异构系统:
根据CPU和GPU是否共享内存,可分为两种类型的CPU-GPU架构:
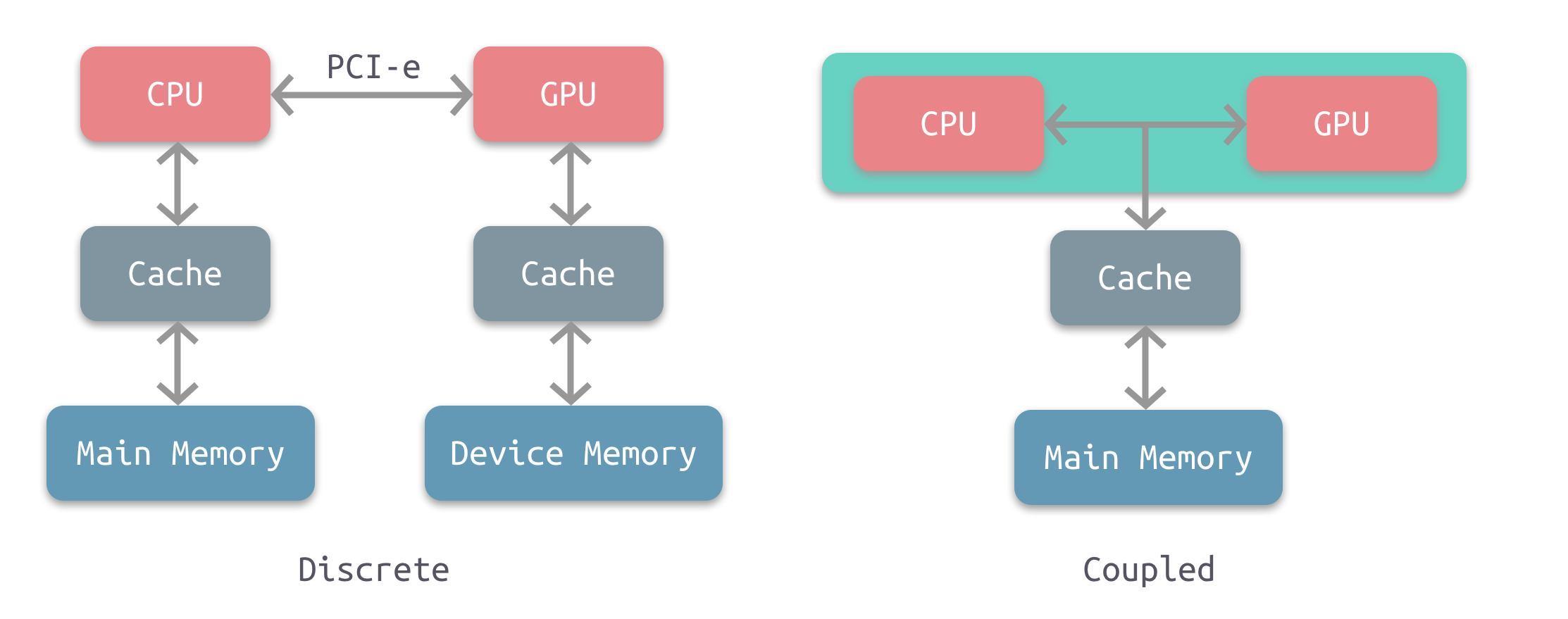
上图左是分离式架构,CPU和GPU各自有独立的缓存和内存,它们通过PCI-e等总线通讯。这种结构的缺点在于 PCI-e 相对于两者具有低带宽和高延迟,数据的传输成了其中的性能瓶颈。目前使用非常广泛,如PC、智能手机等。
上图右是耦合式架构,CPU 和 GPU 共享内存和缓存。AMD 的 APU 采用的就是这种结构,目前主要使用在游戏主机中,如 PS4。
在存储管理方面,分离式结构中 CPU 和 GPU 各自拥有独立的内存,两者共享一套虚拟地址空间,必要时会进行内存拷贝。对于耦合式结构,GPU 没有独立的内存,与 GPU 共享系统内存,由 MMU 进行存储管理。
CPU-GPU数据流
下图是分离式架构的CPU-GPU的数据流程图:

1、将主存的处理数据复制到显存中。
2、CPU指令驱动GPU。
3、GPU中的每个运算单元并行处理。此步会从显存存取数据。
4、GPU将显存结果传回主存。
显像机制:
水平和垂直同步信号
在早期的CRT显示器,电子枪从上到下逐行扫描,扫描完成后显示器就呈现一帧画面。然后电子枪回到初始位置进行下一次扫描。为了同步显示器的显示过程和系统的视频控制器,显示器会用硬件时钟产生一系列的定时信号。
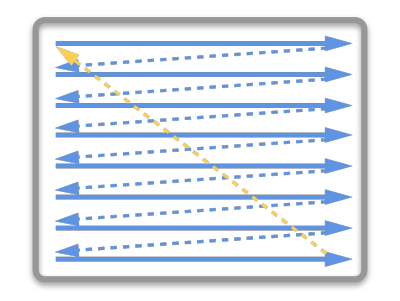
当电子枪换行进行扫描时,显示器会发出一个水平同步信号(horizonal synchronization),简称 HSync
当一帧画面绘制完成后,电子枪回复到原位,准备画下一帧前,显示器会发出一个垂直同步信号(vertical synchronization),简称 VSync。
显示器通常以固定频率进行刷新,这个刷新率就是 VSync 信号产生的频率。虽然现在的显示器基本都是液晶显示屏了,但其原理基本一致。
CPU将计算好显示内容提交至 GPU,GPU 渲染完成后将渲染结果存入帧缓冲区,视频控制器会按照 VSync 信号逐帧读取帧缓冲区的数据,经过数据转换后最终由显示器进行显示。
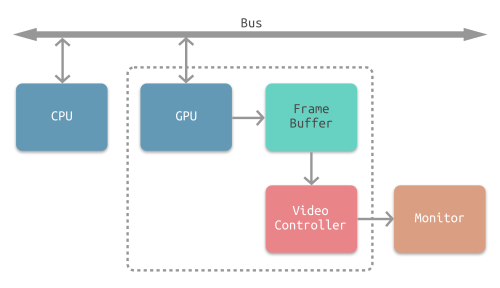
双缓冲
在单缓冲下,帧缓冲区的读取和刷新都都会有比较大的效率问题,经常会出现相互等待的情况,导致帧率下降。
为了解决效率问题,GPU 通常会引入两个缓冲区,即 双缓冲机制。在这种情况下,GPU 会预先渲染一帧放入一个缓冲区中,用于视频控制器的读取。当下一帧渲染完毕后,GPU 会直接把视频控制器的指针指向第二个缓冲器。
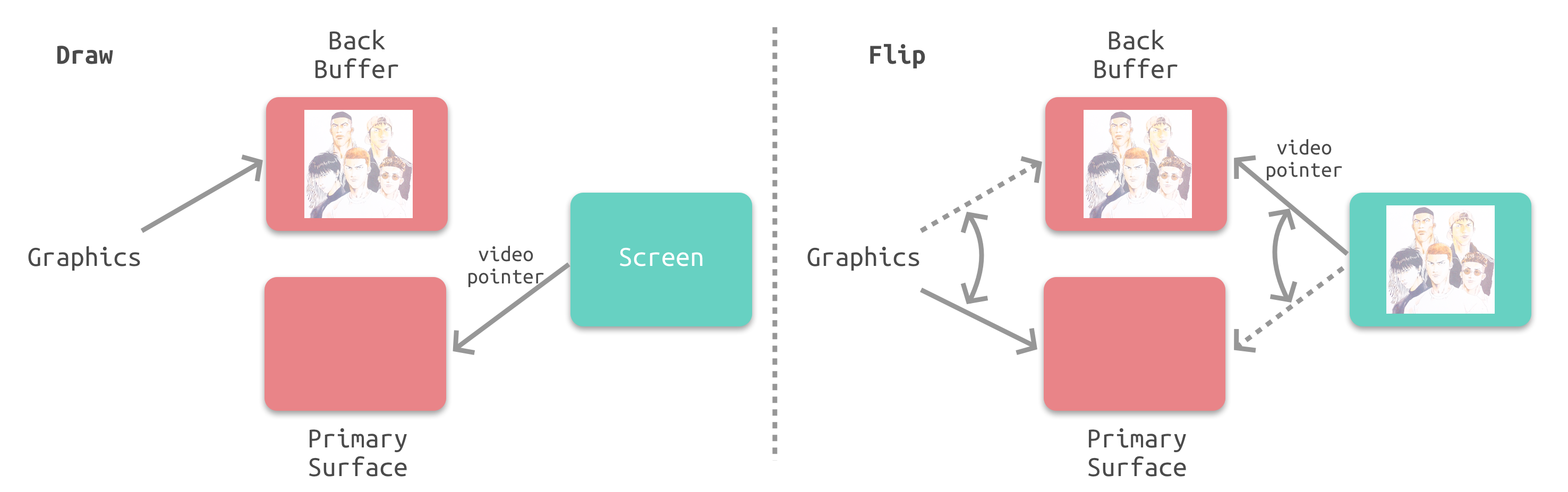
垂直同步
双缓冲虽然能解决效率问题,但会引入一个新的问题。当视频控制器还未读取完成时,即屏幕内容刚显示一半时,GPU 将新的一帧内容提交到帧缓冲区并把两个缓冲区进行交换后,视频控制器就会把新的一帧数据的下半段显示到屏幕上,造成画面撕裂现象:

为了解决这个问题,GPU 通常有一个机制叫做垂直同步(简写也是V-Sync),当开启垂直同步后,GPU 会等待显示器的 VSync 信号发出后,才进行新的一帧渲染和缓冲区更新。这样能解决画面撕裂现象,也增加了画面流畅度,但需要消费更多的计算资源,也会带来部分延迟。
4、cuda c++编程
详细内容看官方技术手册
https://face2ai.com/CUDA-F-1-1-%E5%BC%82%E6%9E%84%E8%AE%A1%E7%AE%97-CUDA/
更具体可以查看:
6、cuda编程常用以及技巧
1、同步

__syncthread();
这个函数完成,这个函数只能同步同一个块内的线程,不能同步不同块内的线程,想要同步不同块内的线程,就只能让核函数执行完成,控制程序交换主机,这种方式来同步所有线程。
内存竞争是非常危险的,一定要非常小心,这里经常出错。
2、错误处理

使用实例:
- 在CUDA API调用处使用
1 | CHECK(cudaMalloc(&d_data, size)); // 检查内存分配 |
2.在核函数调用后使用
1 | myKernel<<<blocks, threads>>>(params); |
3、计算grid的方法
- 在CUDA编程中,计算网格(
grid)尺寸的方式是为了确保所有数据元素都能被线程覆盖,即使数据维度无法被块(block)维度整除。代码中grid的计算公式为:
1 | Cpp |
这种计算方式的原因:
- 向上取整的除法:
- **公式**:`(n-1)/block + 1` 等价于数学上的 **向上取整**(`ceil(n / block)`)。
- **目的**:确保当数据维度(如`nx`或`ny`)无法被块维度(如`block.x`或`block.y`)整除时,仍然分配足够的块来处理所有元素。
- 覆盖所有数据点:
- 每个块的线程数固定(例如`block(4,2)`),但数据维度可能无法整除块维度。例如:
- 若`nx=7`,`block.x=4`,直接除法`7/4=1.75`,但需要2个块才能覆盖所有7个元素。
- 使用`(7-1)/4 +1 = 1 +1 = 2`,确保生成2个块,第二个块处理剩余元素(虽然部分线程可能超出数据范围,但需在核函数中检查边界)。
4、关于GPU的模型框架
https://face2ai.com/CUDA-F-3-1-CUDA%E6%89%A7%E8%A1%8C%E6%A8%A1%E5%9E%8B%E6%A6%82%E8%BF%B0/
SM则包括下面这些资源:
执行单元(CUDA核)
调度线程束的调度器和调度单元
共享内存,寄存器文件和一级缓存
一、SM的硬件组成
- CUDA核心分组
16个CUDA核心为一组:每个SM内部将CUDA核心(即流处理器)按功能或指令类型分组。例如,在Fermi架构中,每个SM包含32个CUDA核心,分为两组,每组16个,分别处理整数和浮点运算。
这种分组允许SM同时执行不同类型的指令(如ALU和FPU操作)
核心类型分工:整数核心处理逻辑运算和地址计算,浮点核心专注于浮点运算,例如在矩阵乘法或物理模拟中。
- 辅助功能单元
16个加载/存储单元:每个SM配备多个独立的内存访问单元,用于处理线程的全局内存读写请求。例如,Fermi架构的SM有16个加载/存储单元,允许每个时钟周期处理16个线程的内存操作
4个特殊功能单元(SFU):SFU负责执行复杂数学运算(如三角函数、指数函数)和原子操作。这些单元与CUDA核心并行工作,加速特定计算场景
二、线程块与线程束的执行逻辑
- 线程块分配到SM后的处理
线程块分割为线程束(Warp):线程块被分配到SM后,会被自动划分为多个线程束(Warp),每个Warp包含32个线程。例如,一个包含256线程的块会被分为8个Warp
Warp调度的必要性:SM的硬件资源(如寄存器、共享内存)有限,无法同时执行所有线程。通过Warp调度器管理多个Warp的交替执行,可隐藏内存访问延迟,提高利用率
- 线程束的交替执行机制
零开销上下文切换:当某个Warp因等待内存访问或分支分歧暂停时,调度器立即切换至其他就绪的Warp,无需保存/恢复寄存器状态,实现无缝切换
SIMT执行模型:同一Warp内的32个线程必须执行相同的指令流。若线程因条件分支出现分歧(如
if-else),SM会串行执行各分支路径,导致性能下降。例如,若半数线程进入
if分支,SM需分两次执行该Warp
三、硬件与软件的协同优化
- 资源分配影响性能
寄存器与共享内存竞争:每个Warp需分配独立寄存器,而共享内存由块内所有线程共享。若块内线程过多,可能导致资源不足,限制SM同时驻留的Warp数量
Bank冲突避免:共享内存分为32个Bank,若同一Warp内多个线程访问同一Bank的不同地址,会导致串行化。编程时需通过内存布局优化(如矩阵转置填充)避免冲突
- 实际应用中的权衡
块大小设计:块的线程数通常设为32的倍数(如128或256),以适配Warp调度机制,减少资源碎片
动态并行与同步:CUDA提供
__syncthreads()实现块内同步,但块间无法直接同步,需通过多次内核启动或原子操作协调
在CUDA架构中,CUDA核心(Streaming Processor, SP)与线程块(Thread Block)是硬件与编程模型的两个关键层级,其关系可从以下角度解析:
一、物理与逻辑的对应关系
- CUDA核心的硬件定位 CUDA核心是GPU的物理计算单元,每个核心负责执行单一线程的算术逻辑运算(ALU/FPU)。例如,在Ampere架构的A100 GPU中,每个SM(流多处理器)包含64个CUDA核心。
- 并行计算能力:单个CUDA核心无法直接对应线程块,但多个CUDA核心通过SIMT(单指令多线程)架构并行执行线程束(Warp)中的指令。
- 线程块的编程模型角色 线程块是逻辑上的线程集合,由程序员定义。每个线程块包含多个线程(如128-1024个),并被分配到一个SM上执行。
- 资源分配:线程块占用SM的共享内存和寄存器资源,例如一个SM最多同时驻留32个线程块(A100 GPU)。
二、执行机制中的交互
- 线程块到CUDA核心的映射
线程束(Warp)划分:线程块被分割为多个32线程的Warp,由SM的Warp调度器分配给CUDA核心执行。例如,一个包含256线程的块会被分为8个Warp。
并行执行:SM中的CUDA核心通过时间片轮转(如Fermi架构每个SM支持48个Warp并发)隐藏指令延迟,实现高效并行。
- 资源竞争与性能优化
寄存器与共享内存限制:每个线程块需分配独立寄存器和共享内存。若线程块过大(如每个线程使用过多寄存器),会限制SM同时处理的块数量,导致资源利用率下降
最佳实践:建议线程块大小为32的倍数(适配Warp机制),例如128或256线程/块,以平衡并行度和资源占用
5、CPU的优势
**当我们的程序包含大量的分支判断时,从程序角度来说,程序的逻辑是很复杂的,因为一个分支就会有两条路可以走,如果有10个分支,那么一共有1024条路走,CPU采用流水线话作业,如果每次等到分支执行完再执行下面的指令会造成很大的延迟,所以现在处理器都采用分支预测技术,而CPU的这项技术相对于gpu来说高级了不止一点点,而这也是GPU与CPU的不同,设计初衷就是为了解决不同的问题。CPU适合逻辑复杂计算量不大的程序,比如操作系统,控制系统,GPU适合大量计算简单逻辑的任务,所以被用来算数。**
6、分支预测
当一个线程束的32个线程执行这段代码的时候,如果其中16个执行if中的代码段,而另外16个执行else中的代码块,同一个线程束中的线程,执行不同的指令,这叫做线程束的分化。
我们知道在每个指令周期,线程束中的所有线程执行相同的指令,但是线程束又是分化的,所以这似乎是相悖的,但是事实上这两个可以不矛盾。
解决矛盾的办法就是每个线程都执行所有的if和else部分,当一部分con成立的时候,执行if块内的代码,有一部分线程con不成立,那么他们怎么办?继续执行else?不可能的,因为分配命令的调度器就一个,所以这些con不成立的线程等待,就像分水果,你不爱吃,那你就只能看着别人吃,等大家都吃完了,再进行下一轮(也就是下一个指令)线程束分化会产生严重的性能下降。条件分支越多,并行性削弱越严重。
注意线程束分化研究的是一个线程束中的线程,不同线程束中的分支互不影响。
因为线程束分化导致的性能下降就应该用线程束的方法解决,根本思路是避免同一个线程束内的线程分化,而让我们能控制线程束内线程行为的原因是线程块中线程分配到线程束是有规律的而不是随机的。这就使得我们根据线程编号来设计分支是可以的,补充说明下,当一个线程束中所有的线程都执行if或者,都执行else时,不存在性能下降;只有当线程束内有分歧产生分支的时候,性能才会急剧下降。
线程束内的线程是可以被我们控制的,那么我们就把都执行if的线程塞到一个线程束中,或者让一个线程束中的线程都执行if,另外线程都执行else的这种方式可以将效率提高很多。
7、关于内存分配

8、关于充分利用线程以及避免分支分化
通过重新映射,使得一个线程束里面的全部线程全部活跃,另外一个线程束不工作,提高效率。
9、cuda性能分析
使用nsys操作
1. 基础用法
1.1 生成性能分析报告
1 | nsys profile [选项] ./your_cuda_program |
默认输出:生成
report.qdrep(二进制文件)和report.sqlite(数据库文件)。查看概要统计:
1 | nsys stats report.qdrep # 显示关键指标汇总 |
1.2 常用选项
| 选项 | 说明 | |
|---|---|---|
-o <文件名> |
指定输出文件名(默认 report) |
|
--stats=true |
输出统计摘要(类似旧版 nvprof) |
|
--trace=cuda,osrt |
跟踪 CUDA API 和操作系统事件 | |
--force-overwrite=true |
覆盖已有报告文件 |
2. 跟踪特定事件
2.1 跟踪范围控制
- 跟踪 CUDA 活动:
1 | nsys profile --trace=cuda ./your_program |
- 跟踪 CPU 系统调用:
1 | nsys profile --trace=osrt ./your_program |
多类事件组合:
1
nsys profile --trace=cuda,cublas,nvtx ./your_program
2.2 时间范围限定
分析程序特定阶段的性能:
1 | nsys profile --capture-range=cudaProfilerApi --capture-range-end=stop ./your_program |
需在代码中添加范围标记:
1 | cudaProfilerStart(); // 开始记录 |
3. 硬件计数器与指标
3.1 收集 GPU 硬件指标
1 | nsys profile --gpu-metrics=device=0,metric1,metric2 ./your_program |
- 示例(收集 SM 效率和内存带宽):
1 | nsys profile --gpu-metrics=device=0,sm__throughput.avg.pct_of_peak_sustained,smsp__cycles_active.avg.pct_of_peak_sustained ./your_program |
- 查看支持的指标:
1 | nsys profile --list-gpu-metrics |
3.2 收集 CPU 性能数据
1 | nsys profile --sample=cpu ./your_program |
4. 多进程与多 GPU 分析
4.1 分析 MPI 多进程程序
1 | nsys launch mpirun -n 4 ./your_mpi_program |
生成单独的报告文件(每个进程一个报告)。
4.2 多 GPU 设备分析
1 | nsys profile --cuda-device-range=0-3 ./your_multi_gpu_program |
--cuda-device-range=0,2:仅分析 GPU 0 和 2。
5. 高级分析功能
5.1 统一内存分析
跟踪统一内存(Unified Memory)的页迁移:
1 | nsys profile --unified-memory-profiling=per-process-device ./your_program |
5.2 时间线可视化分析
生成时间线数据并用 GUI 查看:
1 | nsys profile -o timeline ./your_program |
GUI 功能:
查看 CPU/GPU 并行时间线
分析内核与内存传输的重叠情况
标记关键区域(需代码中添加 NVTX 标记)
5.3 添加 NVTX 标记
在代码中插入自定义标记:
1 |
|
生成带 NVTX 的报告:
1 | nsys profile --trace=nvtx ./your_program |
6. 导出与二次分析
6.1 导出为 CSV
1 | nsys export --type=csv timeline.qdrep -o timeline.csv |
导出的事件包括 CUDA API、内核、内存操作等。
6.2 使用 Python 分析
通过 nsys 的 Python API 解析 .sqlite 文件:
1 | import sqlite3 |
7. 实战示例
7.1 分析矩阵乘法性能
1 | nsys profile \ |
分析内容:
内核执行时间线
SM 计算单元利用率
自定义 NVTX 标记区域
7.2 优化内存传输
1 | nsys profile --trace=cuda --stats=true ./memory_bound_program |
检查输出中的 cuda_gpu_mem_time_sum,观察:
HtoD(主机到设备)和DtoH(设备到主机)耗时内存带宽利用率
8、一级缓存编译
在CUDA编译时通过-Xptxas -dlcm=cg启用一级缓存控制,具体命令如下:
1 | nvcc -arch=sm_75 -Xptxas -dlcm=cg your_code.cu -o your_program |
分步解释:
- 架构指定:
1 | -arch=sm_75 # 指定Turing架构(根据实际GPU调整) |
- 必须与GPU计算能力匹配(如RTX 2080用sm_75,A100用sm_80)
- 缓存控制选项:
1 | -Xptxas -dlcm=cg # 加载缓存模式设置 |
dlcm= Device Load Cache Modecg= Cache Global(全局内存访问使用L1缓存)
- 完整编译流程:
1 | # 带L1缓存的编译 |
关键参数说明:
| 选项 | 作用 | 适用场景 |
|---|---|---|
-dlcm=ca |
强制所有加载通过L1缓存 | 有数据局部性的访问模式 |
-dlcm=cg |
绕过L1直接使用L2缓存 | 无重用的大步长访问 |
-dlcm=cs |
流式加载(自动缓存策略) | 默认模式 |
验证方法:
- 查看PTX汇编确认效果:
1 | nvcc -arch=sm_75 --ptxas-options=-v -Xptxas -dlcm=cg -ptx main.cu |
输出中观察:
1 | lca::CG // 表示使用全局缓存模式 |
- 性能对比测试:
1 | ./aligned_cached 0 # 对齐访问+L1缓存 |
典型性能差异(RTX 3080测试):
| 访问模式 | L1缓存 | 带宽利用率 | 执行时间 |
|---|---|---|---|
| 对齐 | 启用 | 92% | 1.2ms |
| 对齐 | 禁用 | 88% | 1.3ms |
| 非对齐 | 启用 | 68% | 2.1ms |
| 非对齐 | 禁用 | 72% | 1.9ms |
1.BP神经网络
2.Transformer基础
3.卷积神经网络(CNN)
4.YOLO原理
5.机器学习一些进阶知识
6.tensorRT基础操作
7.MQTT 与 HTTP 通信协议对比及项目应用场景选择
8.机器学习基础知识总结