YOLO原理
本文主要介绍了YOLO目标检测的结构以及原理
YOLO目标检测
YOLO目标检测的目的:
给定一张图片或者一帧视频,设计好模型定位图片中我们感兴趣的物体,同时标注其所属类别
目标检测的原理和算法:

目标检测基本框架:
Backbone network: 主干网络,实现从图像检测中提取出必要的特征信息,然后利用特征去实现定位和分类。
常见主干网络模型
| 网络名 | 特点 | 用途示例 |
|---|---|---|
| VGG | 堆叠简单卷积层,结构规则 | 早期检测器(如 SSD) |
| ResNet | 引入残差连接,解决深层退化问题 | Faster R-CNN, Mask R-CNN |
| MobileNet | 深度可分离卷积,轻量高效 | 适用于移动端模型部署 |
| EfficientNet | 复合缩放策略,精度与效率均衡 | 轻量检测器如 YOLOv7-tiny |
| DenseNet | 层间全连接,特征复用强 | 特征提取、语义分割任务 |
| CSPNet | 改进的梯度流与参数分离策略 | YOLOv4/v5/YOLOv8 主干 |
| Swin Transformer | 视觉Transformer结构,支持长程建模 | 最新版本检测器(如 DINO) |
关于ResNet
引言
在深度学习中,随着网络层数的加深,模型表现并不总是提升,反而可能出现退化问题——更深的网络训练误差反而更高。为了解决这一问题,微软研究院于 2015 年提出了 ResNet(Residual Network),成为深度网络设计的里程碑。
ResNet 的核心思想:残差连接
传统卷积网络学习的是:
$$
y = \mathcal{F}(x)
$$
ResNet 则改为学习:
$$
y = \mathcal{F}(x) + x
$$
其中:
- ( x ):输入特征
- $$( \mathcal{F}(x) )$$ 残差映射(通常是若干层卷积)
- $$( x + \mathcal{F}(x) )$$ 称为残差连接或跳跃连接(skip connection)
这种结构允许信息直接“跳过”卷积层,缓解梯度消失、退化等问题。
ResNet的本质就是,加上x,做恒等映射,把之前网络的梯度传递下来,使得梯度可以保留,同时x可以为0,即没有学到任何信息最优输出为自己本身,不会对模型造成影响。
加上残差连接(+x)后,网络在前向传播中保留了原始输入特征,在反向传播中确保了梯度能直接传回前层,避免梯度消失,从而使网络更容易训练、可以加深,并能高效学习“偏离输入”的差异,而不是从零开始学习全部映射。
ResNet 的基本模块:残差块(Residual Block)
标准残差块结构如下图所示:
1 | Input |
Neck Network(颈部网络)位于检测模型的 Backbone(主干网络)与 Head(检测头)之间,是连接提取与预测的桥梁。
其主要作用是:
- 多尺度特征融合:整合来自不同层次的语义和空间信息;
- 增强上下文感知能力:提升模型对大物体、小物体的识别能力;
- 信息传导通路:为后续分类与定位提供统一格式的特征张量。
为什么需要 Neck?
主干网络输出的特征通常存在分辨率差异:
- 高层特征:语义强但空间分辨率低(适合识别整体类别);
- 低层特征:空间精度高但语义弱(适合定位边缘或小目标);
Neck 的任务就是将这些不同层级的特征进行融合与传递,使得检测头可以“既懂语义,又知细节”。
常见 Neck 结构对比
| 结构 | 全称 | 特点说明 |
|---|---|---|
| FPN | Feature Pyramid Network | 自顶向下特征融合,提升小目标检测能力 |
| PANet | Path Aggregation Network | 引入自底向上路径,增强位置敏感特征 |
| BiFPN | Bidirectional Feature Pyramid | 双向融合 + 加权特征选择,用于高效检测 |
| YOLO-Nano Neck | C2f + SPPF + upsample/concat | YOLOv8 使用轻量结构实现高效上下文建模 |
关于FPN :
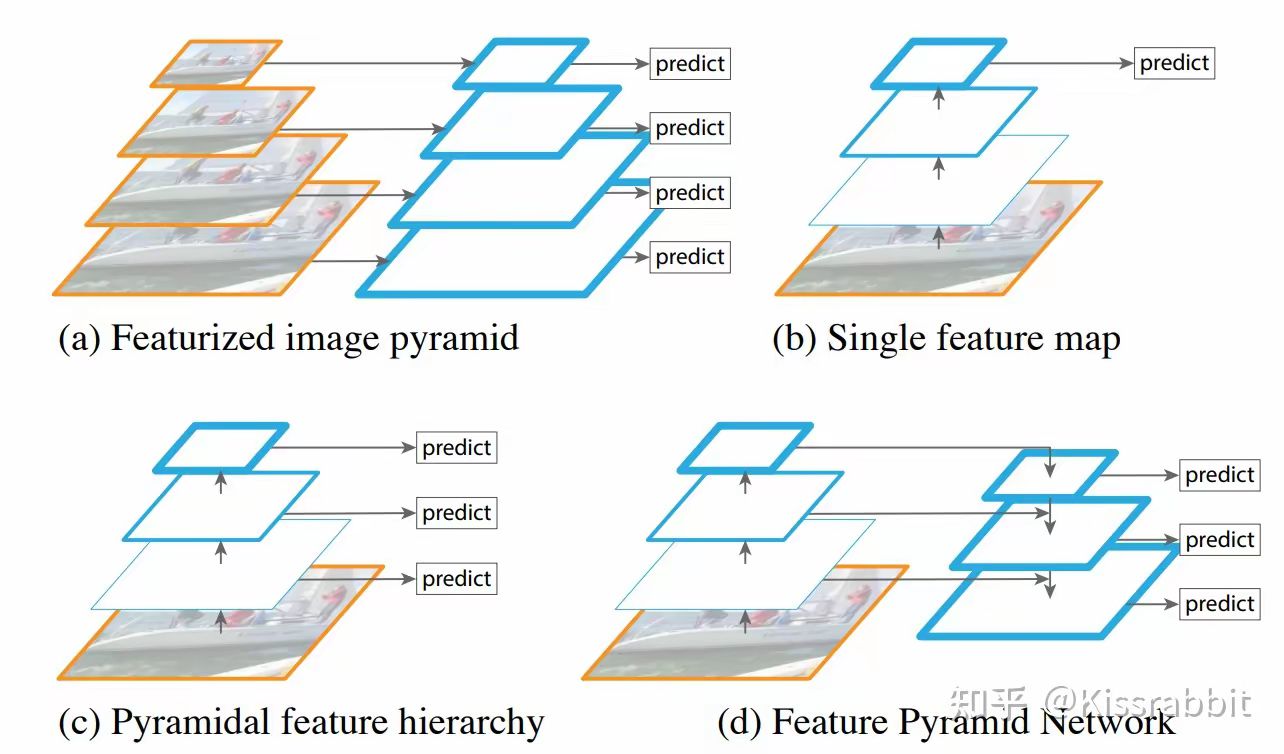
FPN就是在检测之前,先将多个尺度的特征图进行一次buttom-up的融合
FPN 的工作流程包括三个步骤:
Bottom-up(从低到高)路径:
- 由主干网络(如 ResNet)生成多层级特征图 $$( C_2, C_3, C_4, C_5 )$$
- 特征越往上越抽象、越语义化。
Top-down(从高到低)路径:
- 从顶层特征开始,逐层进行上采样(放大图像)(如 nearest 或 bilinear);
- 每一级都与相应的 bottom-up 特征图横向连接(1×1卷积后相加);
- 实现语义信息的向下传递。
横向连接(Lateral connections):
- 在每一层使用卷积对底层特征进行通道变换;
- 与上采样后的高层语义特征相加,完成融合。
融合后的特征图记为 ( P_2, P_3, P_4, P_5 ),每个尺度都具备了丰富语义 + 精细结构,非常适合目标检测中的多尺度预测任务。
应用场景
- 小目标检测(提升显著)
- 多尺度目标检测(如 RetinaNet、Mask R-CNN)
- YOLO 系列中也借鉴 FPN 原理构建 Neck(如 PANet)
关于SPP(Spatial Pyramid Pooling)空间金字塔池化
SPP(空间金字塔池化) 是一种用于增强神经网络感受野的结构,最早应用于图像分类任务中,后来在 YOLOv3~YOLOv5 等目标检测模型中广泛使用。
它的目标是:在不改变输入尺寸的前提下,提取多尺度空间信息并融合,从而提升模型对不同大小目标的识别能力。
为什么需要 SPP?
传统的卷积 + 池化结构只能捕捉固定尺度的局部信息,但目标可能有不同的形状和大小,SPP 提供了一种多尺度上下文建模方式:
- 小池化核:捕捉局部精细结构;
- 大池化核:感知全局上下文区域。
通过多尺度池化输出连接,模型能同时理解图像的局部细节和整体语义。
SPP 工作原理
SPP 模块会在一张特征图上,并行使用多个不同大小的池化核(如 5×5、9×9、13×13),然后将它们的输出与原始特征图进行 拼接(concat)。
1 | 输入特征图 |
池化(Pooling)操作详解
在卷积神经网络(CNN)中,池化(Pooling) 是一种用于降低特征图空间维度的操作,能够压缩信息、减少计算量,并提升模型的平移不变性和鲁棒性。
1. 池化的作用
- 降低特征图尺寸(减少内存占用与计算负担)
- 提取主干特征(保留最显著的响应)
- 增强局部不变性(使模型对位置偏移更鲁棒)
- 防止过拟合(通过信息压缩减少冗余)
2. 常见池化类型
| 类型 | 说明 |
|---|---|
| 最大池化(Max Pooling) | 每个滑动窗口中取最大值 |
| 平均池化(Average Pooling) | 每个窗口取平均值 |
| 全局平均池化(Global Average Pooling) | 整个特征图平均,变为一个数 |
3. 池化操作示意
以 2×2 最大池化为例:
1 | 输入特征图(4×4): |
Detection Head:负责定位与检测
Detection Head(检测头) 是目标检测模型中最终完成预测的模块,接收来自 Backbone + Neck 网络融合后的多尺度特征图,输出每个位置上的分类结果和回归坐标。
检测头的作用
检测头对特征图进行卷积,目的是从每个位置提取该位置是否存在目标、目标属于哪类、目标框的位置这些局部感知信息。
- 分类分支:判断该位置上属于哪个类别(或是否为前景);
- 回归分支:预测边界框的位置参数(通常是中心坐标 + 宽高,或偏移量形式);
- 通常每个尺度特征图都单独接一个检测头,多尺度检测能力来源于此。
结构特点
检测头通常非常简单,主要由几层小卷积 + 输出层构成:
- 不需要复杂结构;
- 不进行特征提取,仅负责最终特征转输出;
- 通常是轻量的,参数占比不大,但作用关键。
检测头本质上就是在每一个特征图位置上卷积滑窗计算分类和回归输出。它结构简单,执行高效,但承担着模型预测的全部核心逻辑。
RetinaNet 中的检测头示意
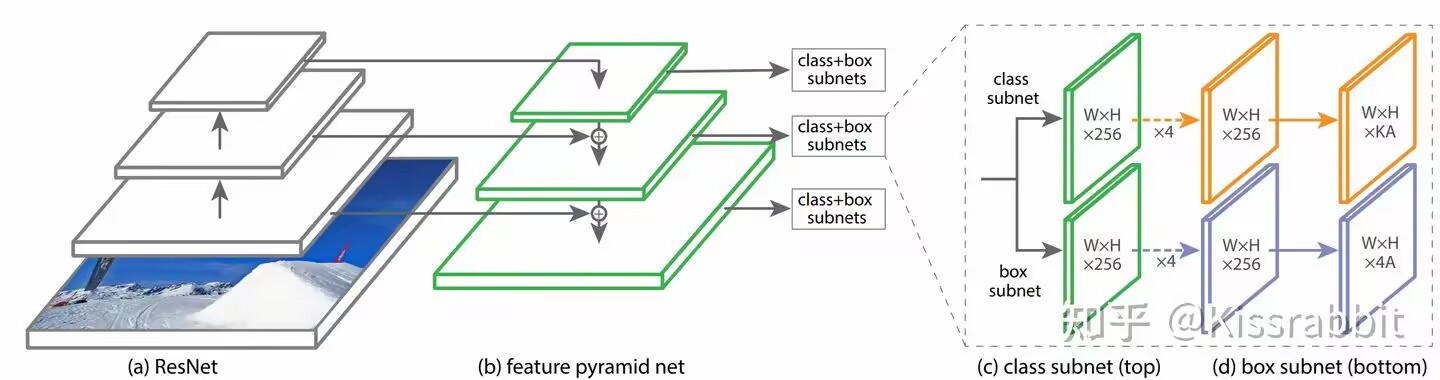
在 RetinaNet 中:
- 每个 FPN 层输出的特征图都接两个独立分支:
- 一个分类头(Class Head):多个 3×3 卷积 + sigmoid 输出
- 一个回归头(Box Head):多个 3×3 卷积 + 边界框输出
两者结构相似,但参数不共享,各自独立优化。
YOLOV8训练时候的参数指标:
| 指标名 | 含义 | 常见范围 | 说明 |
|---|---|---|---|
box_loss |
边界框回归损失 | 越低越好 | 表示预测框与真实框之间的差异(如 IoU Loss) |
cls_loss |
分类损失 | 越低越好 | 表示分类误差,通常采用交叉熵 |
dfl_loss |
分布式回归损失 | 边界框回归,预测框的位置分布与真实样本坐标分布接近,越低越好 | 用于增强回归精度 |
loss |
总损失 | 越低越好 | 综合损失,越小模型表现越好 |
mAP50 |
平均精度(IoU=0.5) | [0, 1] | 用于粗略衡量模型检测性能 |
mAP50-95 |
平均精度(IoU=0.5~0.95) | [0, 1] | 更全面、更严格的性能评估指标 |
在目标检测中,预测框和真实框之间的重叠面积占总体面积的比例就是 IoU
🔗 总损失公式
YOLO(以 Ultralytics YOLOv8 为例)的总损失由三项加权求和:
- $$(\mathcal{L}_{\mathrm{box}})$$ 边框回归损失(CIoU/DIoU/GIoU),对应
box_loss - $$(\mathcal{L}_{\mathrm{cls}})$$ 分类损失(Focal Loss 或 BCEWithLogitsLoss),对应
cls_loss - $$(\mathcal{L}_{\mathrm{dfl}})$$ Distribution Focal Loss,对应
dfl_loss
$$(\lambda_{\mathrm{box}}, \lambda_{\mathrm{cls}}, \lambda_{\mathrm{dfl}}) $$是在 hyp.yaml 中定义的权重,用于平衡三者。
⚙️ 默认超参数权重
Ultralytics YOLOv8 默认的损失权重设置如下:
1 | hyp: |
参数介绍
1. Loss 趋势
- 初期 loss 应迅速下降;
- 中后期趋于平稳或缓慢下降;
- 若 loss 不降反升,可能出现梯度爆炸或过拟合。
2. mAP 表现
mAP50-95 > 0.5表示模型基本合格;mAP > 0.7可视为优秀模型;mAP50较高但mAP50-95较低可能说明检测框偏差大。
3. 收敛与过拟合
- 验证 mAP 多轮无提升或下降:考虑早停或调参;
- 验证集 mAP 下降但训练集 loss 持续下降:过拟合信号。
YOLO参数解读
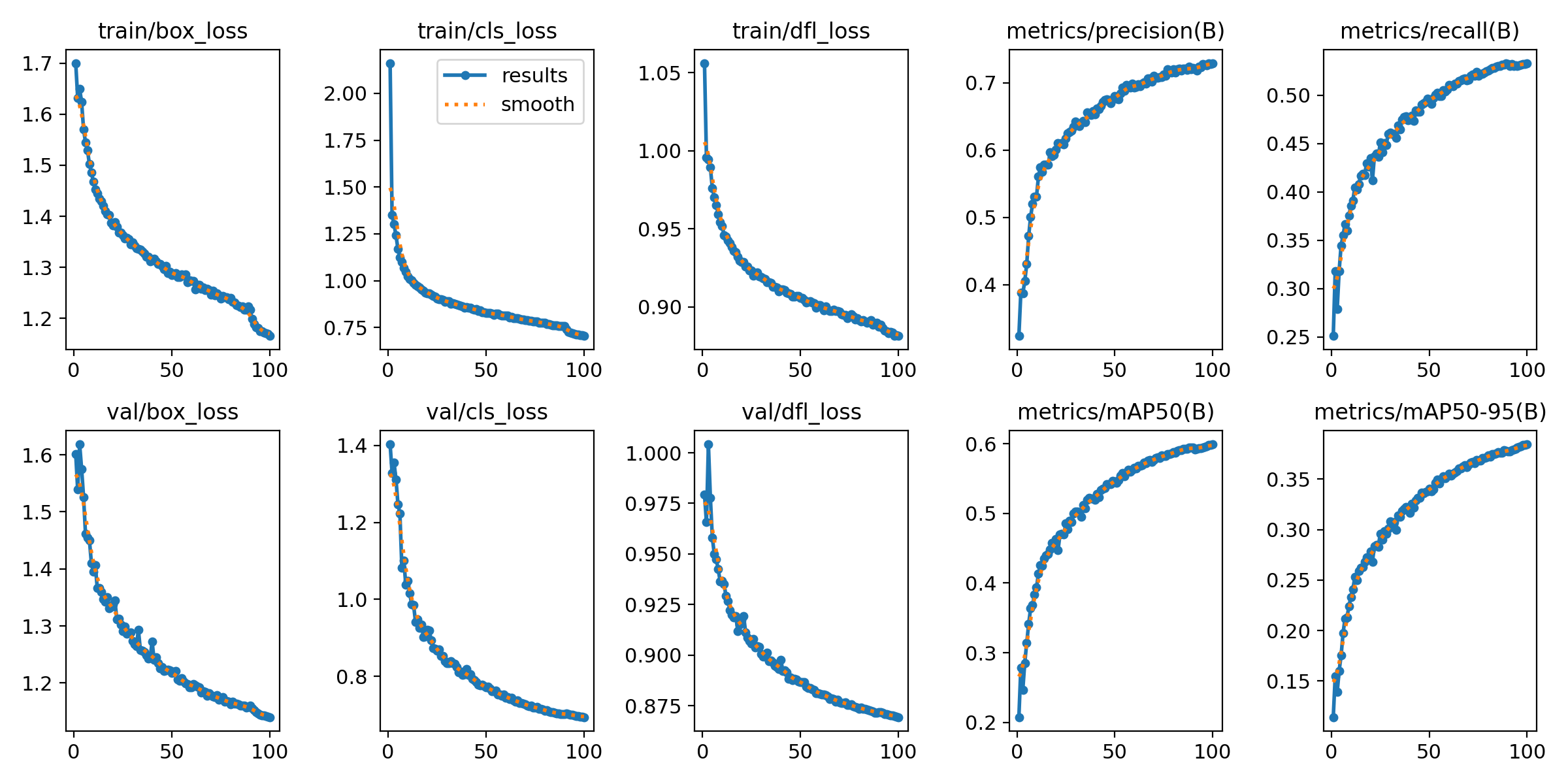
📉 训练与验证损失(Loss)分析
损失函数衡量的是模型预测与实际标注之间的差距,下降趋势表明模型正在逐步学习正确的特征。
train/box_loss 与 val/box_loss
- 定义:边框回归损失,用于衡量预测框与真实框之间的位置差异。
- 变化趋势:逐渐下降,表明模型定位能力在逐步增强。
train/cls_loss 与 val/cls_loss
- 定义:分类损失,用于衡量预测类别与真实类别之间的差异。
- 变化趋势:前期快速下降,后期趋于平稳,说明模型快速掌握基本分类规则,并进行精细调整。
train/dfl_loss 与 val/dfl_loss
- 定义:分布式焦点损失(Distribution Focal Loss),优化边框回归精度。
- 变化趋势:整体稳步下降,表明预测框的定位精度持续提升。
📊 模型性能评估指标(Metrics)
在目标检测任务中,评估指标直接体现模型在真实应用场景中的表现。
metrics/precision(B)
- 定义:精确率,表示预测为正的样本中实际为正的比例。
- 趋势:持续上升,误检率降低,模型预测更精准。
metrics/recall(B)
- 定义:召回率,表示所有真实正样本中被正确识别的比例。
- 趋势:逐步上升,说明模型对正样本的覆盖能力增强。
metrics/mAP50(B)
- 定义:在 IoU 阈值为 0.5 时的平均精度均值(Mean Average Precision)。
- 趋势:由初期的 0.2 上升至 0.6,说明模型准确度显著提升。
metrics/mAP50-95(B)
- 定义:多个 IoU 阈值(0.5 至 0.95)下的平均精度,更严格的衡量标准。
- 趋势:逐步提升,从 0.15 增至 0.37,显示模型在严格要求下也具有良好表现。
1.BP神经网络
2.Transformer基础
3.卷积神经网络(CNN)
4.机器学习一些进阶知识
5.tensorRT基础操作
6.Cuda基础操作
7.MQTT 与 HTTP 通信协议对比及项目应用场景选择
8.机器学习基础知识总结